
当散列表遇上链表,会碰撞出怎样的火花?
启辰源码在算法设计的世界里,散列表与单链表的结合应用尤为常见。以java中的LinkedHashMap为例,它巧妙地将散列表和单链表融为一体,为数据处理带来了全新的可能。那么,这两者是如何携手共舞的?它们又能激荡出哪些创新的浪花呢?请跟随我的步伐,一同探寻其中的奥秘。
我们先来思考一个挑战:如何使用单链表来实现LRU缓存机制?如果你对LRU(最近最少使用)缓存策略还不太熟悉,建议先了解一下页面置换算法的相关知识。
我们可以维护一个有序的单链表,其中越靠近尾部的节点代表越近期被访问的数据。当有新数据被访问时,我们从链表头开始遍历。如果数据已在链表中,我们找到对应节点并将其移动到链表头部;如果数据不在链表中,且链表未满,我们直接将该节点插入链表头部;若链表已满,则先从尾部删除一个节点,再将新数据节点插入到链表头部。
这样,我们就利用单链表实现了一个简单的LRU缓存。但你是否想过,有什么方法可以降低这一操作的时间复杂度呢?缓存操作主要涉及添加、删除和查找三个步骤,而单纯使用单链表在这三个操作上的时间复杂度均为O(n)。然而,散列表的查找操作却能达到惊人的O(1)时间复杂度。那么,我们能否将散列表与单链表有机结合,使得这三个缓存操作的平均时间复杂度也降至O(1)呢?答案是肯定的,让我们来一探究竟。
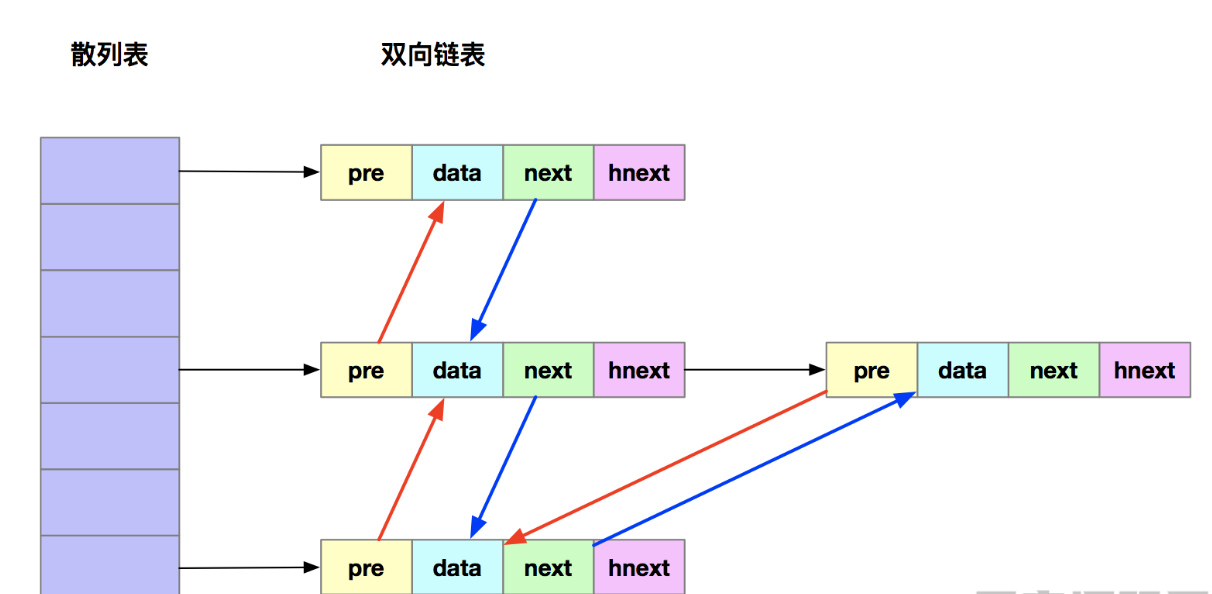
我们采用双向链表来存储数据,每个节点除了包含常规的数据、前驱指针和后继指针外,还增加了一个特殊的字段hnext。这个hnext字段有何妙用呢?原来,我们的散列表是采用链表法来处理冲突的,因此每个节点实际上会同时存在于这两条链中:一条是双向链表,另一条则是散列表中的拉链。前驱和后继指针用于将节点串接在双向链表中,而hnext指针则负责将节点串接在散列表的拉链上。
了解了这种组合存储结构后,我们再回头看看那三缓存操作是如何保证O(1)时间复杂度的。首先是数据查找。由于散列表的查找操作近乎O(1),因此我们可以在缓存中快速定位数据。一旦找到数据,我们还需要将其移动到双向链表的尾部,以更新其访问顺序。这一步操作同样可以在常数时间内完成。其次是数据删除。我们需要先通过散列表快速定位要删除的节点,然后利用双向链表的特点,在常数时间内完成节点的删除操作。最后是数据添加。添加数据时,我们首先检查数据是否已存在缓存中,如果存在则移动至链表头部;如果不存在且缓存未满,则直接添加到链表头部;若缓存已满,则需先删除链表尾部的节点,再添加新数据。整个过程中,查找操作均可通过散列表高效完成。
综上所述,通过将散列表与双向链表巧妙结合,我们不仅实现了高效的LRU缓存替换算法,还将三个关键操作的时间复杂度均降为了O(1)。这场散列表与链表的精彩碰撞,无疑为我们探索算法优化和数据结构设计提供了新的思路和灵感。
2. 您必须在下载后的24个小时之内,从您的电脑中彻底删除上述内容资源!
3. 如果你也有好源码或者教程,可以到审核区发布,分享有金币奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 本站不保证所提供下载的资源的准确性、安全性和完整性,源码仅供下载学习之用!
8. 如用于商业或者非法用途,与本站无关,一切后果请用户自负!
启辰源码 - 一站式源码与模板下载平台 » 当散列表遇上链表,会碰撞出怎样的火花?





